Best Travel Wallets for 2026: Secure Your Passport, Cards, and Cash Without the Bulk
June 21, 2026

Travel wallets (also called passport wallets or RFID blocking holders) organize your passport, multiple currencies, credit cards, IDs, boarding passes, and sometimes even a pen or small notes. They range from minimalist cardholders to full zip-around folios. Core Categories: Materials include full-grain leather for premium feel, recycled nylon for lightness, and metal accents for structure. ... Read more
Read more
Coat Rack Buying Guide: Find the Perfect Freestanding or Wall-Mounted Solution That Actually Holds Up
June 21, 2026

Coats pile up on chairs, bags hit the floor, and guests step over the mess the second they walk in. A good coat rack fixes that chaos instantly. It gives every jacket, scarf, and umbrella a proper home while adding personality to your space. In 2026, with smaller homes and busier lives, these simple pieces ... Read more
Read more
AI Hardware News 2026: The Biggest Breakthroughs, Chips, and What They Mean for You
June 20, 2026

AI hardware revolves around accelerators optimized for the parallel math that powers neural networks. The big shift: moving beyond general-purpose CPUs to specialized designs that handle tensors, matrix multiplications, and inference efficiently. Primary entities: Secondary factors: High-Bandwidth Memory (HBM), chiplets, advanced packaging, power delivery, cooling infrastructure, and software ecosystems like CUDA. Related terms you’ll see ... Read more
Read more
Eyelash Mites Explained: Symptoms, Safe Treatments, and Prevention for Healthy Eyes in 2026
June 19, 2026
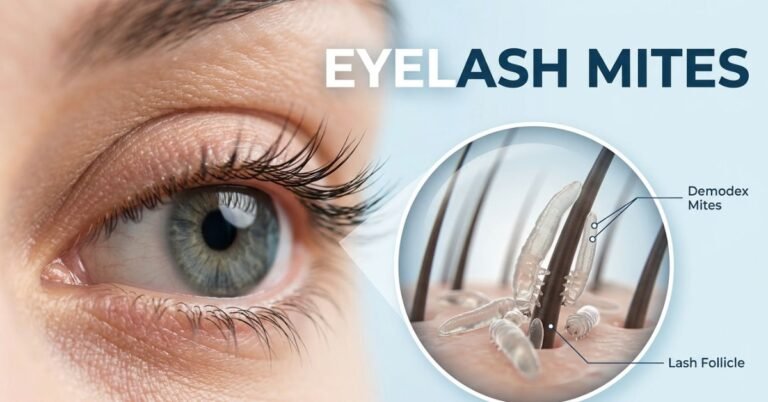
Eyelash mites (Demodex folliculorum and Demodex brevis) are microscopic arachnids, cigar-shaped and about 0.3 mm long, invisible to the naked eye. They live in hair follicles and oil glands, feeding on dead skin cells and sebum. They have a short 14-18 day life cycle and emerge mostly at night. Key entities and concepts: Everyone has ... Read more
Read more
Afternoon Tea Done Right: From History to Homemade Scones That Rival the Ritz
June 19, 2026

Afternoon tea traces back to the 1840s and Anna, the Duchess of Bedford. She experienced a “sinking feeling” in the long stretch between lunch and dinner (often served at 8 p.m.), so she requested tea and light refreshments around 4 p.m. What started as a personal fix quickly became a social ritual among the upper ... Read more
Read more
Non-Alcoholic Beer Guide 2026: The Best Tasting Options That Actually Deliver Flavor Without the Buzz
June 17, 2026

Non-alcoholic beer nails that sweet spot for millions right now.In 2026, NA beer (typically under 0.5% ABV) has exploded in quality and variety. Craft brewers like Athletic Brewing have raised the bar so high that many options taste remarkably close to their alcoholic counterparts. The sober-curious movement, wellness trends, and better brewing tech are driving ... Read more
Read more
Best Laptops for Writers 2026: The Perfect Tools for Flow, Focus, and Finishing
June 17, 2026

The best laptops for writers balance comfort for marathon sessions with enough power for research tabs, Scrivener, or cloud syncing without unnecessary weight or distractions. Apple’s M-series chips, premium Windows ultraportables, and durable business machines dominate for good reason. This guide breaks down exactly what matters for writers, the current top performers across budgets, and ... Read more
Read more
English Lavender: The Complete Growing Guide for Fragrant, Long-Lasting Blooms
June 16, 2026

English lavender is a flowering perennial herb native to the Mediterranean region.Despite its name, it did not originate in England. The plant earned its common name because it became widely cultivated throughout English gardens and landscapes. Key Characteristics Feature Details Botanical Name Lavandula angustifolia Common Name English Lavender Plant Type Perennial Herb Mature Height 18–36 ... Read more
Read more
Lamb’s Ear Plant: The Complete Growing Guide for Soft Silver Ground Cover
June 16, 2026

Few garden plants create instant visual impact quite like the Lamb’s Ear plant. With its velvety silver leaves and remarkably low-maintenance nature, this perennial has become a favorite among homeowners, landscape designers, and drought-conscious gardeners. Known botanically as Stachys byzantina, Lamb’s Ear is prized for its soft texture, ability to thrive in difficult conditions, and ... Read more
Read more
Eyebrow Threading in 2026: Benefits, Costs, Pain Level, and Expert Tips
June 11, 2026

Eyebrow threading is a hair removal technique that uses a twisted cotton thread to remove unwanted hairs directly from the follicle.The thread is rolled across the skin, catching and lifting individual hairs with remarkable precision.Unlike waxing, threading does not involve chemicals, heat, or adhesive products.This makes it especially appealing for individuals with sensitive skin. The ... Read more
Read more